"Every week, I watched designers redraw the same diagram—like déjà vu with arrows."
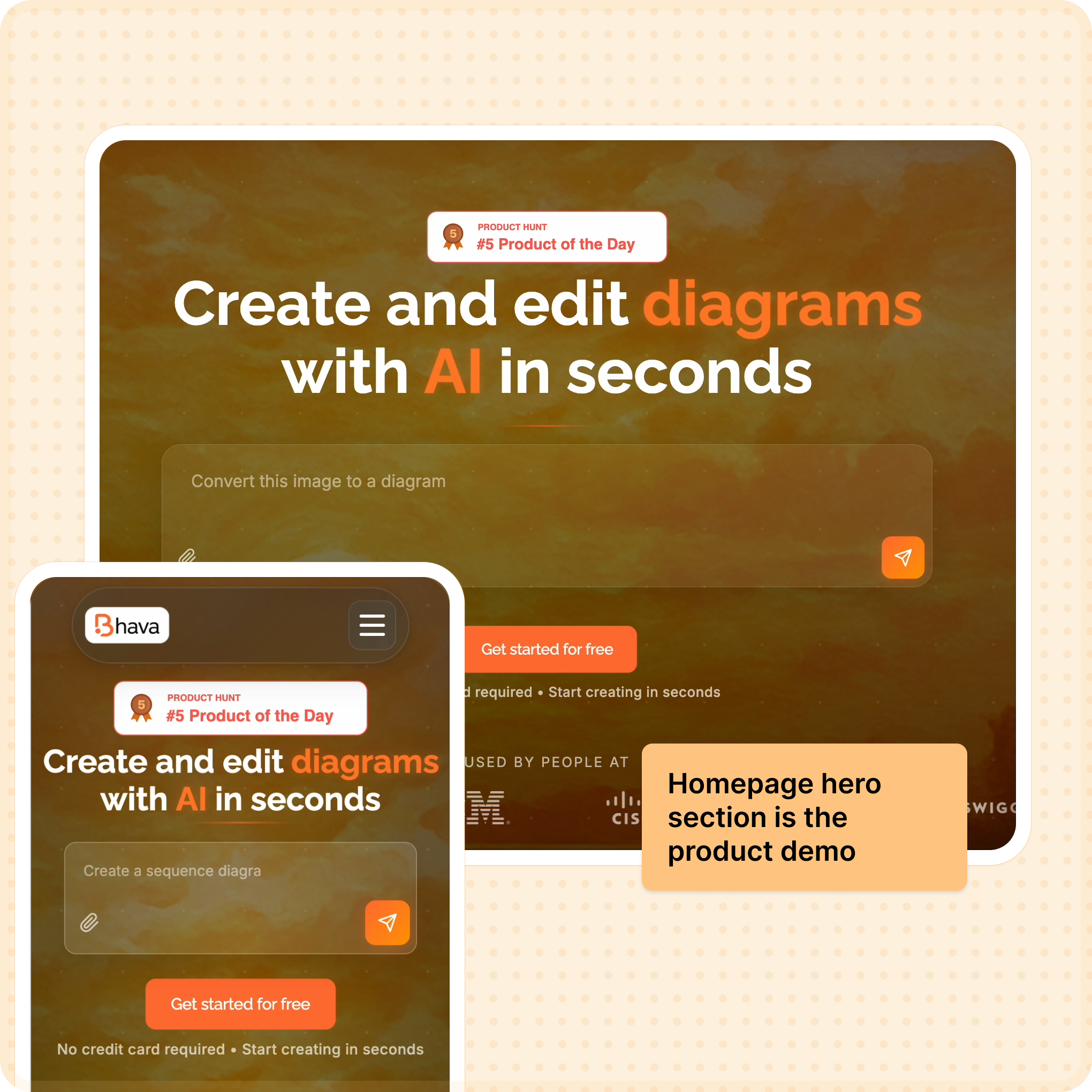
By day, I'm deep in B2B dashboards. By night, I watch my team waste hours redrawing the same system diagram in Figma, Draw.io, Excalidraw, and Miro.
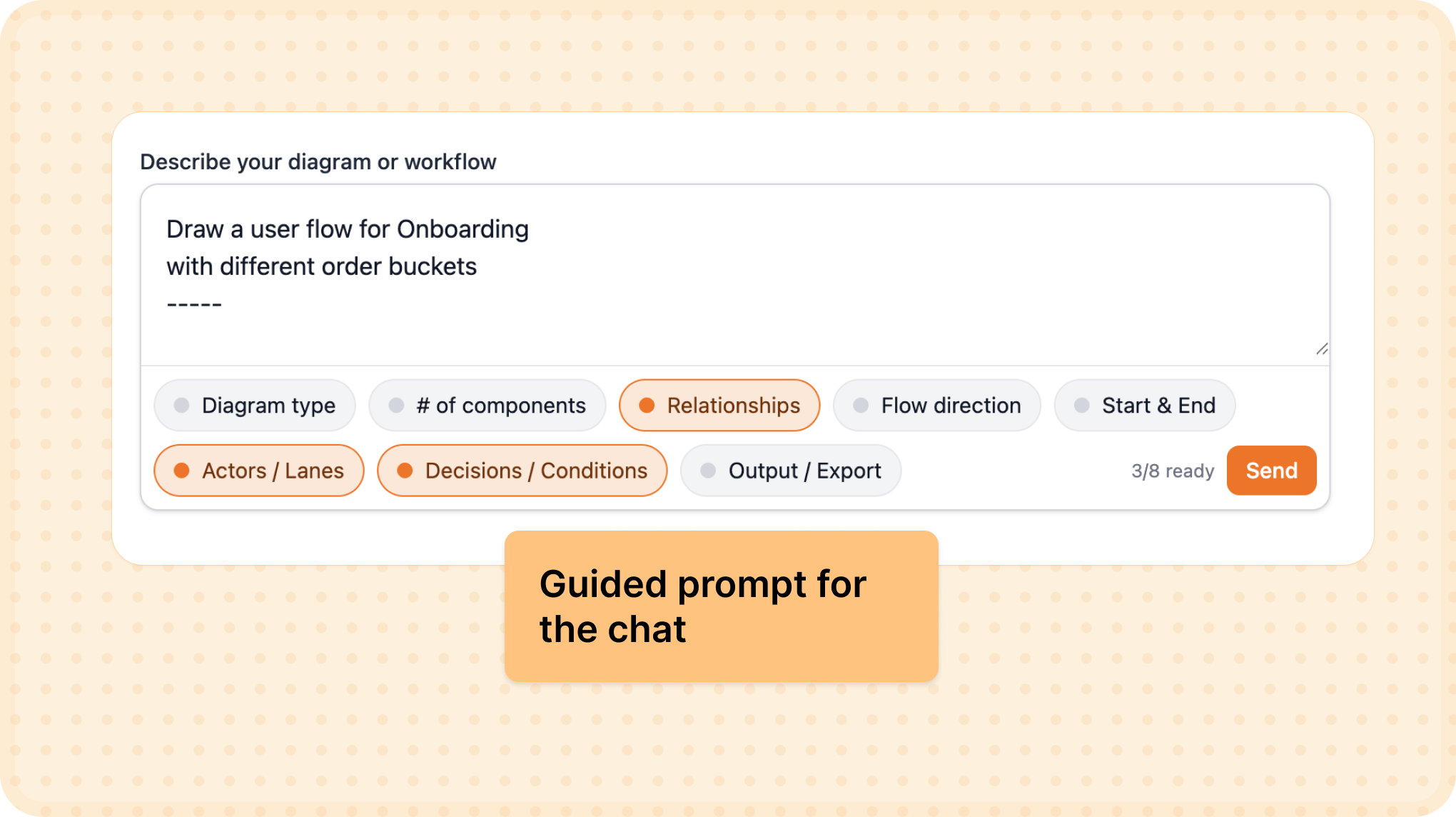
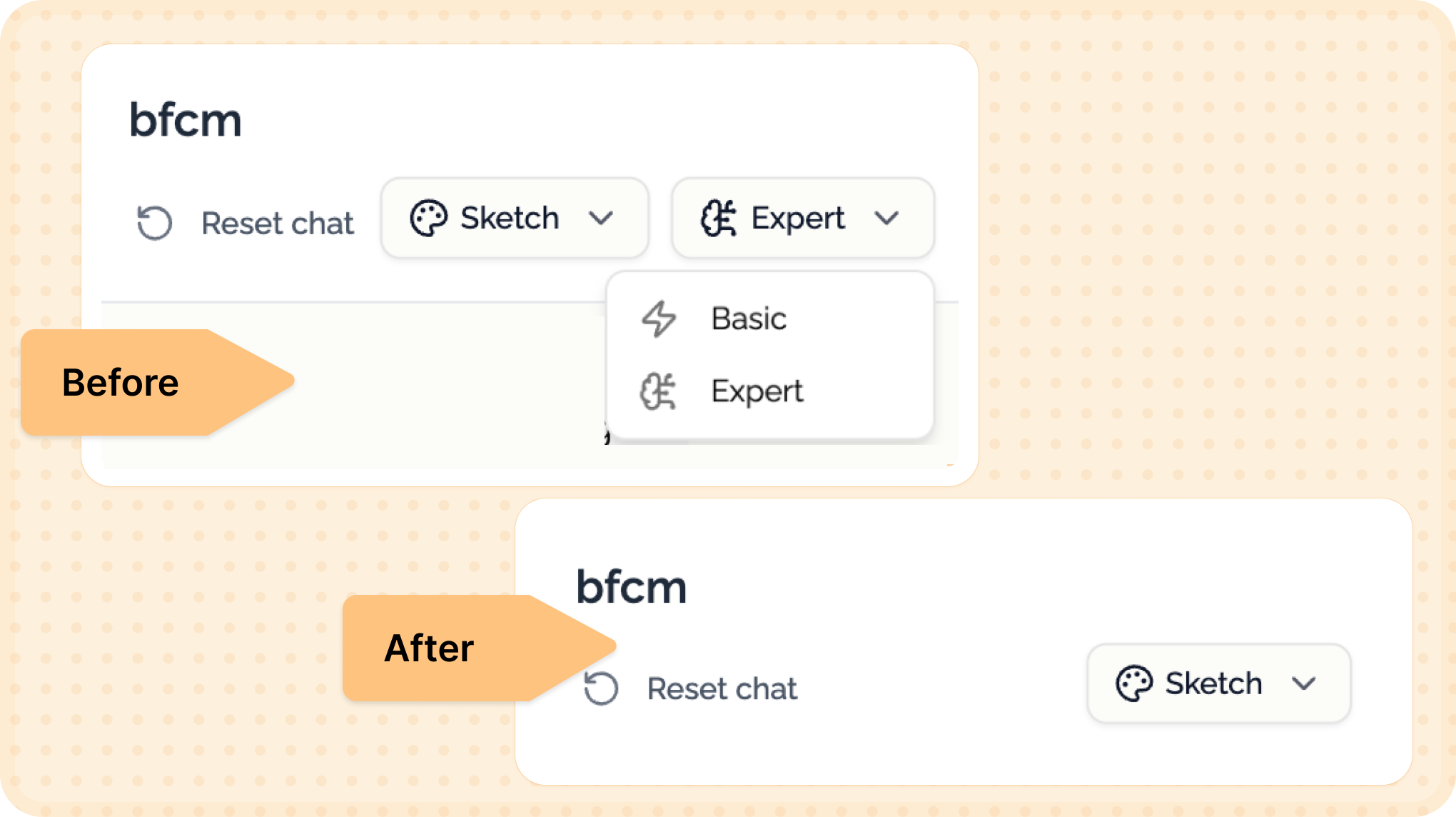
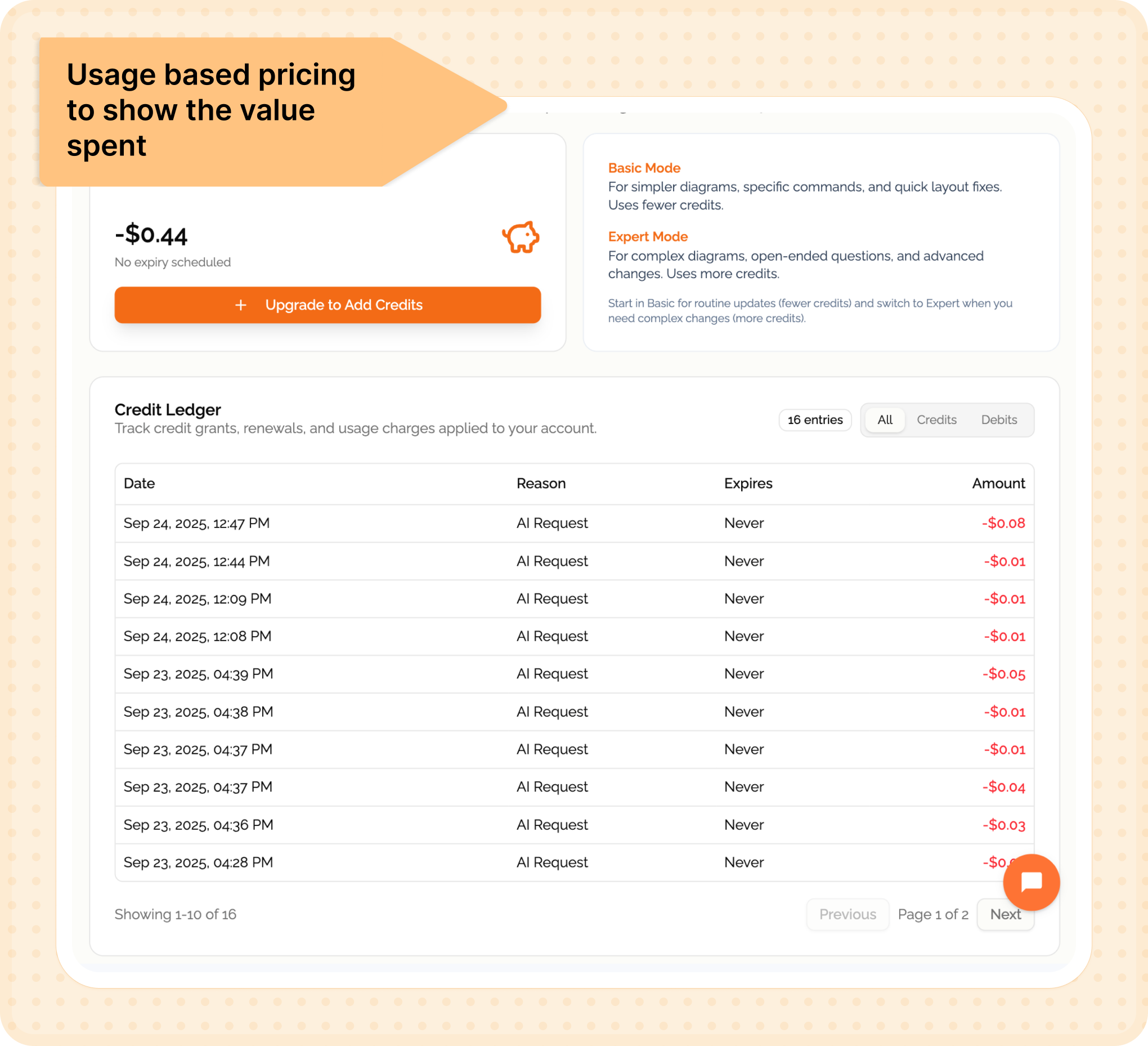
So I started building Bhava—an AI tool that generates diagrams instantly.